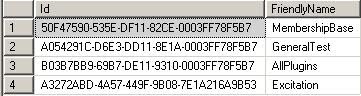
In Dynamics 365 Online, you may have recently noticed a new button within an unmanaged solution, 'Solution Layers'. I first saw this appear around 17th Mar 2019, and it's a welcome tool to help understand more what happens with multiple solutions in a system.

I've been playing around with this a bit in the last week, and there are a few key concepts to understand from the beginning.
- The button is currently only visible within an unmanaged solution or the default solution. This seems to be because managed solutions are not directly editable, though I think this is a bit of an oversight, because...
- When you click the button for a solution component, it will display any managed solutions that contain that component, along with an 'Active' solution. From what I can tell so far, I'm treating the 'Active' solution to be the same as the default solution, but there may be subtle differences
- It makes sense that this only displays managed solutions, as these are the only one solutions that a individually layered. In contrast, unmanaged solutions are all combined into the one unmanaged layer
So, it's a little confusing to start with, in that you can only access it from the unmanaged layer, but it is displaying information about the managed layers. But, leaving that aside, what does it tell us ? It provides information at 2 levels; first the list of layers, then the detail properties that were set within that layer.
The Layers
When you click on the 'Solution Layers' button, it will list all the managed solutions that contain this component, and the order in which they apply.
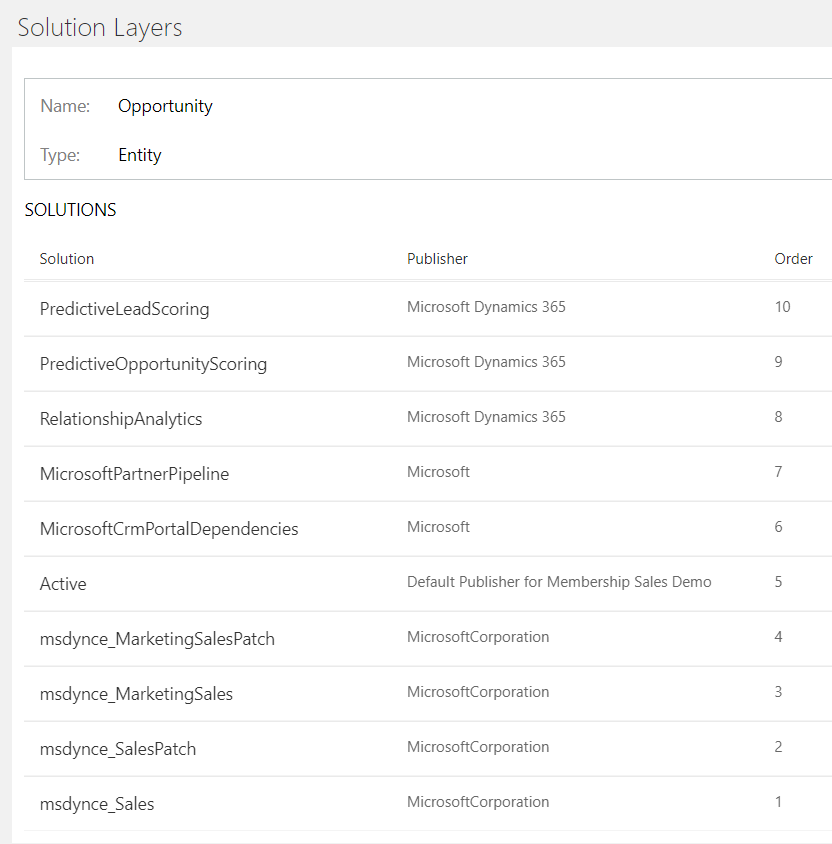
Order no.1 is the first solution in which this component was imported into this organisation, with the remaining solutions in incremental order. The order listed is the order in which any changes will be applied; I think this would normally be the order in which the solutions are installed, though I suspect that Microsoft may change the order of some of their solutions, irrespective of the installation sequence. So, we start with order = 1, then any changes from each other solution are applied in turn, so that a change from a higher Ordered solution would override a change to the same property in a lower Ordered solution.
So, the information we get here is what solutions contain a component, and the order of the solutions. The interesting thing here is that some layers appear above the Active layer; from what I can tell so far, only solutions from Microsoft appear above the Active layer.
Properties within a Layer
If you click on a layer, it will then show the component properties within this layer. The 'Changed Properties' tab shows the component properties within this layer, and what value they were set to in this layer.

So, in this case we see that the msdynce_SalesPatch changes 3 properties of the Opportunity entity, for example the isauditenabled property. This indicates that the 'Include Entity Metadata' option had been selected when the entity had been added to the solution in the source system, which is one of the useful pieces of information that we can now get from the Solution Layer.
The 'All Properties' tab shows all the effective properties at this layer - i.e. taking all properties from layers at a lower order number, and applying the properties from this layer, but these can be overridden by layers with a higher number.

Note that, in the example above for the Opportunity entity, you several solutions were listed, but many don't have any changed properties. I think this is mostly because an entity will be included in a solution because one of its subcomponents (e.g. a view) has changed. To see this, you'd have to open Solution Layers on the subcomponent.
Different component types have different properties. Unfortunately the information given so far is, unsurprisingly, only the whole property. So, for example for a form, we just see the formxml and formjson, and this doesn't give us a representation of how forms are merged across solutions. However, I'm intending to dig further into whether the 'All Properties' tab can give an indication of how the formxml changes through the layers - if I find anything interesting then that could be another blog post